Data Lineage
Lineage capture
Intuitively, for an operator T producing output o, lineage consists of triplets of form {I, T, o}, where I is the set of inputs to T used to derive o. Capturing lineage for each operator T in a dataflow enables users to ask questions such as "Which outputs were produced by an input i on operator T ?" and "Which inputs produced output o in operator T ?" A query that finds the inputs deriving an output is called a backward tracing query, while one that finds the outputs produced by an input is called a forward tracing query. Backward tracing is useful for debugging, while forward tracing is useful for tracking error propagation. Tracing queries also form the basis for replaying an original dataflow. However, to efficiently use lineage in a DISC system, we need to be able to capture lineage at multiple levels (or granularities) of operators and data, capture accurate lineage for DISC processing constructs and be able to trace through multiple dataflow stages efficiently.
DISC system consists of several levels of operators and data, and different use cases of lineage can dictate the level at which lineage needs to be captured. Lineage can be captured at the level of the job, using files and giving lineage tuples of form {IF i, M RJob, OF i }, lineage can also be captured at the level of each task, using records and giving, for example, lineage tuples of form {(k rr, v rr ), map, (k m, v m )}. The first form of lineage is called coarse-grain lineage, while the second form is called fine-grain lineage. Integrating lineage across different granularities enables users to ask questions such as "Which file read by a MapReduce job produced this particular output record?" and can be useful in debugging across different operator and data granularities within a dataflow.
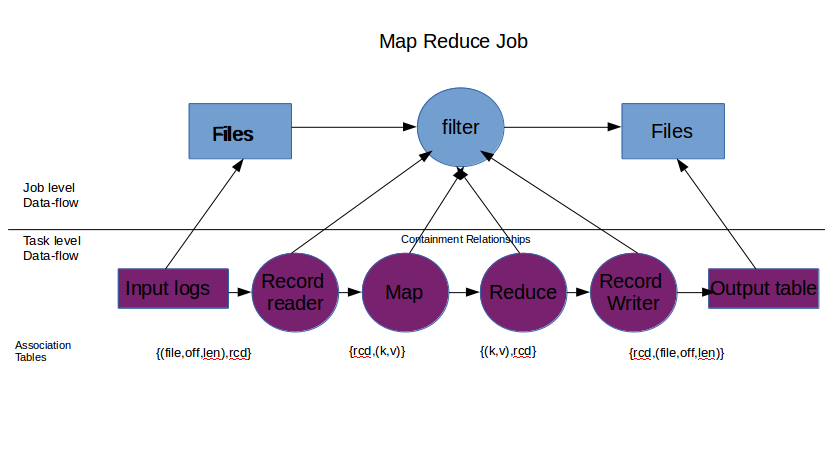
Map Reduce Job showing containment relationships
To capture end-to-end lineage in a DISC system, we use the Ibis model, which introduces the notion of containment hierarchies for operators and data. Specifically, Ibis proposes that an operator can be contained within another and such a relationship between two operators is called operator containment. "Operator containment implies that the contained (or child) operator performs a part of the logical operation of the containing (or parent) operator". For example, a MapReduce task is contained in a job. Similar containment relationships exist for data as well, called data containment. Data containment implies that the contained data is a subset of the containing data (superset).
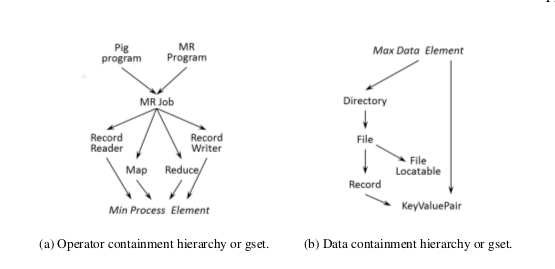
Containment Hierarchy